Linux服务器端编程之高性能服务器架构设计
时间:2020-06-09来源:www.pcxitongcheng.com作者:电脑系统城
所谓高性能就是服务器能流畅地处理各个客户端的连接并尽量低延迟地应答客户端的请求;所谓高并发,指的是服务器可以同时支持多的客户端连接,且这些客户端在连接期间内会不断与服务器有数据来往。
这篇文章将从两个方面来介绍,一个是服务器的框架,即单个服务器程序的代码组织结构;另外一个是一组服务程序的如何组织与交互,即架构。注意:本文以下内容中的客户端是相对概念,指的是连接到当前讨论的服务程序的终端,所以这里的客户端既可能是我们传统意义上的客户端程序,也可能是连接该服务的其他服务器程序。

一、框架篇
按上面介绍的思路,我们先从单个服务程序的组织结构开始介绍。
(一)、网络通信
既然是服务器程序肯定会涉及到网络通信部分,那么服务器程序的网络通信模块要解决哪些问题?
笔者认为至少要解决以下问题:
1. 如何检测有新客户端连接?
2. 如何接受客户端连接?
3. 如何检测客户端是否有数据发来?
4.如何收取客户端发来的数据?
5.如何检测连接异常?发现连接异常之后,如何处理?
6.如何给客户端发送数据?
7.如何在给客户端发完数据后关闭连接?
稍微有点网络基础的人,都能回答上面说的其中几个问题,比如接收客户端连接用socket API的accept函数,收取客户端数据用recv函数,给客户端发送数据用send函数,检测客户端是否有新连接和客户端是否有新数据可以用IO multiplexing技术(IO复用)的select、poll、epoll等socket API。确实是这样的,这些基础的socket API构成了服务器网络通信的地基,不管网络通信框架设计的如何巧妙,都是在这些基础的socket API的基础上构建的。但是如何巧妙地组织这些基础的socket API,才是问题的关键。我们说服务器很高效,支持高并发,实际上只是一个技术实现手段,不管怎样从软件开发的角度来讲无非就是一个程序而已,所以,只要程序能最大可能地满足“尽量减少等待”就是高效。也就是说高效不是“忙的忙死,闲的闲死”,而是大家都可以闲着,但是如果有活要干,大家尽量一起干,而不是一部分忙着依次做事情123456789,另外一部分闲在那里无所事事。说的可能有点抽象,下面我们来举一些例子具体来说明一下。
比如默认recv函数如果没有数据的时候,线程就会阻塞在那里;
默认send函数,如果tcp窗口不是足够大,数据发不出去也会阻塞在那里;
connect函数默认连接另外一端的时候,也会阻塞在那里;
又或者是给对端发送一份数据,需要等待对端回答,如果对方一直不应答,当前线程就阻塞在这里。
以上都不是高效服务器的开发思维方式,因为上面的例子都不满足“尽量减少等待”的原则,为什么一定要等待呢?有没用一种方法,这些过程不需要等待,最好是不仅不需要等待,而且这些事情完成之后能通知我。这样在这些本来用于等待的cpu时间片内,我就可以做一些其他的事情。有,也就是我们下文要讨论的IO Multiplexing技术(IO复用技术)。
(二)、几种IO复用机制的比较
目前windows系统支持select、WSAAsyncSelect、WSAEventSelect、完成端口(IOCP),linux系统支持select、poll、epoll。这里我们不具体介绍每个具体的函数的用法,我们来讨论一点深层次的东西,以上列举的API函数可以分为两个层次:
层次一 select和poll
层次二 WSAAsyncSelect、WSAEventSelect、完成端口(IOCP)、epoll
为什么这么分呢?先来介绍第一层次,select和poll函数本质上还是在一定时间内主动去查询socket句柄(可能是一个也可能是多个)上是否有事件,比如可读事件,可写事件或者出错事件,也就是说我们还是需要每隔一段时间内去主动去做这些检测,如果在这段时间内检测出一些事件来,我们这段时间就算没白花,但是倘若这段时间内没有事件呢?我们只能是做无用功了,说白了,还是在浪费时间,因为假如一个服务器有多个连接,在cpu时间片有限的情况下,我们花费了一定的时间检测了一部分socket连接,却发现它们什么事件都没有,而在这段时间内我们却有一些事情需要处理,那我们为什么要花时间去做这个检测呢?把这个时间用在做我们需要做的事情不好吗?所以对于服务器程序来说,要想高效,我们应该尽量避免花费时间主动去查询一些socket是否有事件,而是等这些socket有事件的时候告诉我们去处理。这也就是层次二的各个函数做的事情,它们实际相当于变主动查询是否有事件为当有事件时,系统会告诉我们,此时我们再去处理,也就是“好钢用在刀刃”上了。只不过层次二的函数通知我们的方式是各不相同,比如WSAAsyncSelect是利用windows消息队列的事件机制来通知我们设定的窗口过程函数,IOCP是利用GetQueuedCompletionStatus返回正确的状态,epoll是epoll_wait函数返回而已。
比如connect函数连接另外一端,如果连接socket是异步的,那么connect虽然不能立刻连接完成,但是也是会立刻返回,无需等待,等连接完成之后,WSAAsyncSelect会返回FD_CONNECT事件告诉我们连接成功,epoll会产生EPOLLOUT事件,我们也能知道连接完成。甚至socket有数据可读时,WSAAsyncSelect产生FD_READ事件,epoll产生EPOLLIN事件,等等。所以有了上面的讨论,我们就可以得到网络通信检测可读可写或者出错事件的正确姿势。这是我这里提出的第二个原则:尽量减少做无用功的时间。这个在服务程序资源够用的情况下可能体现不出来什么优势,但是如果有大量的任务要处理,个人觉得这个可能带来无用
(三)、检测网络事件的正确姿势
根据上面的介绍,第一,为了避免无意义的等待时间,第二,不采用主动查询各个socket的事件,而是采用等待操作系统通知我们有事件的状态的策略。我们的socket都要设置成异步的。在此基础上我们回到栏目(一)中提到的七个问题:
1. 如何检测有新客户端连接?
2. 如何接受客户端连接?
默认accept函数会阻塞在那里,如果epoll检测到侦听socket上有EPOLLIN事件,或者WSAAsyncSelect检测到有FD_ACCEPT事件,那么就表明此时有新连接到来,这个时候调用accept函数,就不会阻塞了。当然产生的新socket你应该也设置成非阻塞的。这样我们就能在新socket上收发数据了。
3. 如何检测客户端是否有数据发来?
4.如何收取客户端发来的数据?
同理,我们也应该在socket上有可读事件的时候才去收取数据,这样我们调用recv或者read函数时不用等待,至于一次性收多少数据好呢?我们可以根据自己的需求来决定,甚至你可以在一个循环里面反复recv或者read,对于非阻塞模式的socket,如果没有数据了,recv或者read也会立刻返回,错误码EWOULDBLOCK会表明当前已经没有数据了。示例:
- bool CIUSocket::Recv()
- {
- int nRet = 0;
- while(true)
- {
- char buff[512];
- nRet = ::recv(m_hSocket, buff, 512, 0);
- if(nRet == SOCKET_ERROR) //一旦出现错误就立刻关闭Socket
- {
- if (::WSAGetLastError() == WSAEWOULDBLOCK)
- break;
- else
- return false;
- }
- else if(nRet < 1)
- return false;
- m_strRecvBuf.append(buff, nRet);
- ::Sleep(1);
- }
- return true;
- }
5.如何检测连接异常?发现连接异常之后,如何处理?
同样当我们收到异常事件后例如EPOLLERR或关闭事件FD_CLOSE,我们就知道了有异常产生,我们对异常的处理一般就是关闭对应的socket。另外,如果send/recv或者read/write函数对一个socket进行操作时,如果返回0,那说明对端已经关闭了socket,此时这路连接也没必要存在了,我们也可以关闭对应的socket。
6.如何给客户端发送数据?
给客户端发送数据,比收数据要稍微麻烦一点,也是需要讲点技巧的。首先我们不能像检测数据可读一样检测数据可写,因为如果检测可写的话,一般情况下只要对端正常收取数据,我们的socket就都是可写的,如果我们设置监听可写事件,会导致频繁地触发可写事件,但是我们此时并不一定有数据需要发送。所以正确的做法是:如果有数据要发送,则先尝试着去发送,如果发送不了或者只发送出去部分,剩下的我们需要将其缓存起来,然后设置检测该socket上可写事件,下次可写事件产生时,再继续发送,如果还是不能完全发出去,则继续设置侦听可写事件,如此往复,一直到所有数据都发出去为止。一旦所有数据都发出去以后,我们要移除侦听可写事件,避免无用的可写事件通知。不知道你注意到没有,如果某次只发出去部分数据,剩下的数据应该暂且存起来,这个时候我们就需要一个缓冲区来存放这部分数据,这个缓冲区我们称为“发送缓冲区”。发送缓冲区不仅存放本次没有发完的数据,还用来存放在发送过程中,上层又传来的新的需要发送的数据。为了保证顺序,新的数据应该追加在当前剩下的数据的后面,发送的时候从发送缓冲区的头部开始发送。也就是说先来的先发送,后来的后发送。
7.如何在给客户端发完数据后关闭连接?
这个问题比较难处理,因为这里的“发送完”不一定是真正的发送完,我们调用send或者write函数即使成功,也只是向操作系统的协议栈里面成功写入数据,至于能否被发出去、何时被发出去很难判断,发出去对方是否收到就更难判断了。所以,我们目前只能简单地认为send或者write返回我们发出数据的字节数大小,我们就认为“发完数据”了。然后调用close等socket API关闭连接。关闭连接的话题,我们再单独开一个小的标题来专门讨论一下。
(四)被动关闭连接和主动关闭连接
在实际的应用中,被动关闭连接是由于我们检测到了连接的异常事件,比如EPOLLERR,或者对端关闭连接,send或recv返回0,这个时候这路连接已经没有存在必要的意义了,我们被迫关闭连接。
而主动关闭连接,是我们主动调用close/closesocket来关闭连接。比如客户端给我们发送非法的数据,比如一些网络攻击的尝试性数据包。这个时候出于安全考虑,我们关闭socket连接。
(五)发送缓冲区和接收缓冲区
上面已经介绍了发送缓冲区了,并说明了其存在的意义。接收缓冲区也是一样的道理,当收到数据以后,我们可以直接进行解包,但是这样并不好,理由一:除非一些约定俗称的协议格式,比如http协议,大多数服务器的业务的协议都是不同的,也就是说一个数据包里面的数据格式的解读应该是业务层的事情,和网络通信层应该解耦,为了网络层更加通用,我们无法知道上层协议长成什么样子,因为不同的协议格式是不一样的,它们与具体的业务有关。理由二:即使知道协议格式,我们在网络层进行解包处理对应的业务,如果这个业务处理比较耗时,比如读取磁盘文件,或者连接数据库进行账号密码验证,那么我们的网络线程会需要大量时间来处理这些任务,这样其它网络事件可能没法及时处理。鉴于以上二点,我们确实需要一个接收缓冲区,将收取到的数据放到该缓冲区里面去,并由专门的业务线程或者业务逻辑去从接收缓冲区中取出数据,并解包处理业务。
说了这么多,那发送缓冲区和接收缓冲区该设计成多大的容量?这是一个老生常谈的问题了,因为我们经常遇到这样的问题:预分配的内存太小不够用,太大的话可能会造成浪费。怎么办呢?答案就是像string、vector一样,设计出一个可以动态增长的缓冲区,按需分配,不够还可以扩展。
需要特别注意的是,这里说的发送缓冲区和接收缓冲区是每一个socket连接都存在一个。这是我们最常见的设计方案。
(六)协议的设计
除了一些通用的协议,如http、ftp协议以外,大多数服务器协议都是根据业务制定的。协议设计好了,数据包的格式就根据协议来设置。我们知道tcp/ip协议是流式数据,所以流式数据就是像流水一样,数据包与数据包之间没有明显的界限。比如A端给B端连续发了三个数据包,每个数据包都是50个字节,B端可能先收到10个字节,再收到140个字节;或者先收到20个字节,再收到20个字节,再收到110个字节;也可能一次性收到150个字节。这150个字节可以以任何字节数目组合和次数被B收到。所以我们讨论协议的设计第一个问题就是如何界定包的界线,也就是接收端如何知道每个包数据的大小。目前常用有如下三种方法:
固定大小,这种方法就是假定每一个包的大小都是固定字节数目,比如上文中讨论的每个包大小都是50个字节,接收端每收气50个字节就当成一个包;
指定包结束符,比如以一个\r\n(换行符和回车符)结束,这样对端只要收到这样的结束符,就可以认为收到了一个包,接下来的数据是下一个包的内容;
指定包的大小,这种方法结合了上述两种方法,一般包头是固定大小,包头中有一个字段指定包体或者整个大的大小,对端收到数据以后先解析包头中的字段得到包体或者整个包的大小,然后根据这个大小去界定数据的界线。
协议要讨论的第二个问题是,设计协议的时候要尽量方便解包,也就是说协议的格式字段应该尽量清晰明了。
协议要讨论的第三个问题是,根据协议组装的数据包应该尽量小,这样有如下好处:第一、对于一些移动端设备来说,其数据处理能力和带宽能力有限,小的数据不仅能加快处理速度,同时节省大量流量费用;第二、如果单个数据包足够小的话,对频繁进行网络通信的服务器端来说,可以大大减小其带宽压力,其所在的系统也能使用更少的内存。试想:假如一个股票服务器,如果一只股票的数据包是100个字节或者1000个字节,那100只股票和10000只股票区别呢?
协议要讨论的第二个问题是,对于数值类型,我们应该显式地指定数值的长度,比如long型,如果在32位机器上是32位的4个字节,但是如果在64位机器上,就变成了64位8个字节了。这样同样是一个long型,发送方和接收方可能会用不同的长度去解码。所以建议最好,在涉及到跨平台使用的协议最好显式地指定协议中整型字段的长度,比如int32,int64等等。下面是一个协议的接口的例子:
- class BinaryReadStream
- {
- private:
- const char* const ptr;
- const size_t len;
- const char* cur;
- BinaryReadStream(const BinaryReadStream&);
- BinaryReadStream& operator=(const BinaryReadStream&);
- public:
- BinaryReadStream(const char* ptr, size_t len);
- virtual const char* GetData() const;
- virtual size_t GetSize() const;
- bool IsEmpty() const;
- bool ReadString(string* str, size_t maxlen, size_t& outlen);
- bool ReadCString(char* str, size_t strlen, size_t& len);
- bool ReadCCString(const char** str, size_t maxlen, size_t& outlen);
- bool ReadInt32(int32_t& i);
- bool ReadInt64(int64_t& i);
- bool ReadShort(short& i);
- bool ReadChar(char& c);
- size_t ReadAll(char* szBuffer, size_t iLen) const;
- bool IsEnd() const;
- const char* GetCurrent() const{ return cur; }
- public:
- bool ReadLength(size_t & len);
- bool ReadLengthWithoutOffset(size_t &headlen, size_t & outlen);
- };
- class BinaryWriteStream
- {
- public:
- BinaryWriteStream(string* data);
- virtual const char* GetData() const;
- virtual size_t GetSize() const;
- bool WriteCString(const char* str, size_t len);
- bool WriteString(const string& str);
- bool WriteDouble(double value, bool isNULL = false);
- bool WriteInt64(int64_t value, bool isNULL = false);
- bool WriteInt32(int32_t i, bool isNULL = false);
- bool WriteShort(short i, bool isNULL = false);
- bool WriteChar(char c, bool isNULL = false);
- size_t GetCurrentPos() const{ return m_data->length(); }
- void Flush();
- void Clear();
- private:
- string* m_data;
- };
其中BinaryWriteStream是编码协议的类,BinaryReadStream是解码协议的类。可以按下面这种方式来编码和解码。
编码:
- std::string outbuf;
- BinaryWriteStream writeStream(&outbuf);
- writeStream.WriteInt32(msg_type_register);
- writeStream.WriteInt32(m_seq);
- writeStream.WriteString(retData);
- writeStream.Flush();
解码:
- BinaryReadStream readStream(strMsg.c_str(), strMsg.length());
- int32_t cmd;
- if (!readStream.ReadInt32(cmd))
- {
- return false;
- }
- //int seq;
- if (!readStream.ReadInt32(m_seq))
- {
- return false;
- }
- std::string data;
- size_t datalength;
- if (!readStream.ReadString(&data, 0, datalength))
- {
- return false;
- }
(七)、服务器程序结构的组织
由于内容过多,后续会单独组织一篇文章详细介绍
二、架构篇
一个项目的服务器端往往由很多服务组成,就算单个服务在性能上做到极致,支持的并发数量也是有限的,举个简单的例子,假如一个聊天服务器,每个用户的信息是1k,那对于一个8G的内存的机器,在不考虑其它的情况下8*1024*1024*1024 / 100 = 1024,实际有838万,但实际这只是非常理想的情况。所以我们有时候需要需要某个服务部署多套,就单个服务的实现来讲还是《框架篇》中介绍的。我们举个例子:
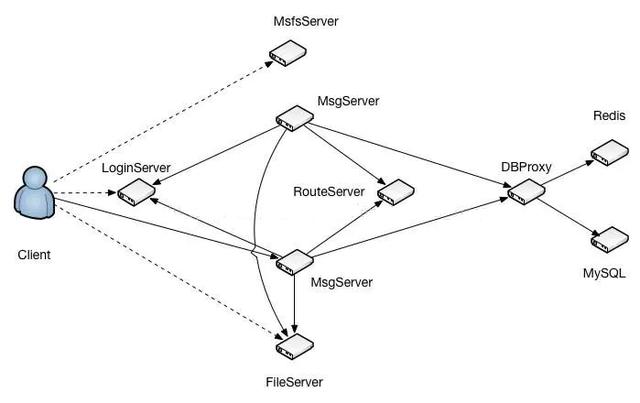
这是蘑菇街TeamTalk的服务器架构。MsgServer是聊天服务,可以部署多套,每个聊天服务器启动时都会告诉loginSever和routeSever自己的ip地址和端口号,当有用户上下或者下线的时候,MsgServer也会告诉loginSever和routeSever自己上面最新的用户数量和用户id列表。现在一个用户需要登录,先连接loginServer,loginServer根据记录的各个MsgServer上的用户情况,返回一个最小负载的MsgServer的ip地址和端口号给客户端,客户端再利用这个ip地址和端口号去登录MsgServer。当聊天时,位于A MsgServer上的用户给另外一个用户发送消息,如果该用户不在同一个MsgServer上,MsgServer将消息转发给RouteServer,RouteServer根据自己记录的用户id信息找到目标用户所在的MsgServer并转发给对应的MsgServer。
上面是分布式部署的一个例子。我们再来看另外一个例子,这个例子是单个服务的策略,实际服务器在处理网络数据的时候,如果同时有多个socket上有数据要处理,可能会出现一直服务前几个socket,直到前几个socket处理完毕后再处理后面几个socket的数据。这就相当于,你去饭店吃饭,大家都点了菜,但是有些桌子上一直在上菜,而有些桌子上一直没有菜。这样肯定不好,我们来看下如何避免这种现象:
- int CFtdEngine::HandlePackage(CFTDCPackage *pFTDCPackage, CFTDCSession *pSession)
- {
- //NET_IO_LOG0("CFtdEngine::HandlePackage\n");
- FTDC_PACKAGE_DEBUG(pFTDCPackage);
- if (pFTDCPackage->GetTID() != FTD_TID_ReqUserLogin)
- {
- if (!IsSessionLogin(pSession->GetSessionID()))
- {
- SendErrorRsp(pFTDCPackage, pSession, 1, "客户未登录");
- return 0;
- }
- }
- CalcFlux(pSession, pFTDCPackage->Length()); //统计流量
- REPORT_EVENT(LOG_DEBUG, "Front/Fgateway", "登录请求%0x", pFTDCPackage->GetTID());
- int nRet = 0;
- switch(pFTDCPackage->GetTID())
- {
- case FTD_TID_ReqUserLogin:
- ///huwp:20070608:检查过高版本的API将被禁止登录
- if (pFTDCPackage->GetVersion()>FTD_VERSION)
- {
- SendErrorRsp(pFTDCPackage, pSession, 1, "Too High FTD Version");
- return 0;
- }
- nRet = OnReqUserLogin(pFTDCPackage, (CFTDCSession *)pSession);
- FTDRequestIndex.incValue();
- break;
- case FTD_TID_ReqCheckUserLogin:
- nRet = OnReqCheckUserLogin(pFTDCPackage, (CFTDCSession *)pSession);
- FTDRequestIndex.incValue();
- break;
- case FTD_TID_ReqSubscribeTopic:
- nRet = OnReqSubscribeTopic(pFTDCPackage, (CFTDCSession *)pSession);
- FTDRequestIndex.incValue();
- break;
- }
- return 0;
- }
当有某个socket上有数据可读时,接着接收该socket上的数据,对接收到的数据进行解包,然后调用CalcFlux(pSession, pFTDCPackage->Length())进行流量统计:
- void CFrontEngine::CalcFlux(CSession *pSession, const int nFlux)
- {
- TFrontSessionInfo *pSessionInfo = m_mapSessionInfo.Find(pSession->GetSessionID());
- if (pSessionInfo != NULL)
- {
- //流量控制改为计数
- pSessionInfo->nCommFlux ++;
- ///若流量超过规定,则挂起该会话的读操作
- if (pSessionInfo->nCommFlux >= pSessionInfo->nMaxCommFlux)
- {
- pSession->SuspendRead(true);
- }
- }
- }
该函数会先让某个连接会话(Session)处理的包数量递增,接着判断是否超过最大包数量,则设置读挂起标志:
- void CSession::SuspendRead(bool bSuspend)
- {
- m_bSuspendRead = bSuspend;
- }
这样下次将会从检测的socket列表中排除该socket:
- void CEpollReactor::RegisterIO(CEventHandler *pEventHandler)
- {
- int nReadID, nWriteID;
- pEventHandler->GetIds(&nReadID, &nWriteID);
- if (nWriteID != 0 && nReadID ==0)
- {
- nReadID = nWriteID;
- }
- if (nReadID != 0)
- {
- m_mapEventHandlerId[pEventHandler] = nReadID;
- struct epoll_event ev;
- ev.data.ptr = pEventHandler;
- if(epoll_ctl(m_fdEpoll, EPOLL_CTL_ADD, nReadID, &ev) != 0)
- {
- perror("epoll_ctl EPOLL_CTL_ADD");
- }
- }
- }
- void CSession::GetIds(int *pReadId, int *pWriteId)
- {
- m_pChannelProtocol->GetIds(pReadId,pWriteId);
- if (m_bSuspendRead)
- {
- *pReadId = 0;
- }
- }
也就是说不再检测该socket上是否有数据可读。然后在定时器里1秒后重置该标志,这样这个socket上有数据的话又可以重新检测到了:
- const int SESSION_CHECK_TIMER_ID = 9;
- const int SESSION_CHECK_INTERVAL = 1000;
- SetTimer(SESSION_CHECK_TIMER_ID, SESSION_CHECK_INTERVAL);
- void CFrontEngine::OnTimer(int nIDEvent)
- {
- if (nIDEvent == SESSION_CHECK_TIMER_ID)
- {
- CSessionMap::iterator itor = m_mapSession.Begin();
- while (!itor.IsEnd())
- {
- TFrontSessionInfo *pFind = m_mapSessionInfo.Find((*itor)->GetSessionID());
- if (pFind != NULL)
- {
- CheckSession(*itor, pFind);
- }
- itor++;
- }
- }
- }
- void CFrontEngine::CheckSession(CSession *pSession, TFrontSessionInfo *pSessionInfo)
- {
- ///重新开始计算流量
- pSessionInfo->nCommFlux -= pSessionInfo->nMaxCommFlux;
- if (pSessionInfo->nCommFlux < 0)
- {
- pSessionInfo->nCommFlux = 0;
- }
- ///若流量超过规定,则挂起该会话的读操作
- pSession->SuspendRead(pSessionInfo->nCommFlux >= pSessionInfo->nMaxCommFlux);
- }
这就相当与饭店里面先给某一桌客人上一些菜,让他们先吃着,等上了一些菜之后不会再给这桌继续上菜了,而是给其它空桌上菜,大家都吃上后,继续回来给原先的桌子继续上菜。实际上我们的饭店都是这么做的。上面的例子是单服务流量控制的实现的一个非常好的思路,它保证了每个客户端都能均衡地得到服务,而不是一些客户端等很久才有响应。
另外加快服务器处理速度的策略可能就是缓存了,缓存实际上是以空间换取时间的策略。对于一些反复使用的,但是不经常改变的信息,如果从原始地点加载这些信息就比较耗时的数据(比如从磁盘中、从数据库中),我们就可以使用缓存。所以时下像redis、leveldb、fastdb等各种内存数据库大行其道。我在flamingo中用户的基本信息都是缓存在聊天服务程序中的,而文件服务启动时会去加载指定目录里面的所有程序名称,这些文件的名称都是md5,为该文件内容的md5。这样当客户端上传了新文件请求时,如果其传上来的文件md5已经位于缓存中,则表明该文件在服务器上已经存在,这个时候服务器就不必再接收该文件了,而是告诉客户端文件已经上传成功了。
说了这么多,一般来说,一个服务器的架构,往往更多取决于其具体的业务,我们要在结合当前的情况来实际去组织铺排,没有一套系统是万能的。多思考,多实践,多总结,相信很快你也能拥有很不错的架构能力。
相关信息
-



-
-
2024-07-07
myeclipse怎么导入tomcat教程 -
2024-07-07
myeclipse如何启动tomcat -
2024-07-07
myeclipse如何绑定tomcat
-
-

-
 Nginx配置-日志格式配置方式
Nginx配置-日志格式配置方式上线了一个小的预约程序,配置通过Nginx进行访问入口,默认的日志是没有请求时间的,因此需要配置一下,将每一次的请求的访问响应时间记录出来,备查与优化使用....
2023-03-17
热门系统总排行
- 8734次 1 雨林木风Win10专业版64位纯净版系统官方下载
- 5408次 2 Win11官方最新版系统下载_Ghost Win11 22000.434(KB5009566)专业免激活版下载
- 4857次 3 电脑公司ghost win7 64位纯净专业版v2019.08
- 3296次 4 最新游戏专用Win11系统下载_游戏专用Ghost Win11 64位极速免激活专业版下载
- 2939次 5 深度技术 GHOST WIN10 X64 纯净版 V2019.09(64位)
- 2721次 6 Win10 21H1 esd镜像系统下载_Win10 21H1 64位免激活官方正式版下载V2021.04
- 2472次 7 深度技术 Ghost Win10 64位 免激活专业稳定版官网下载 V2021.12
- 2330次 8 电脑系统城ghost win7 sp132位 经典标准版 V2019.11












系统教程栏目
栏目热门教程
- 27246次 1 浏览器控制台报错Failed to load module script:解决方法
- 6145次 2 windows server2012上配置IIS全过程(附详细步骤)
- 5690次 3 解决Navicat 连接服务器不成功的问题
- 3671次 4 Nginx访问本地静态资源详细步骤(推荐)
- 3131次 5 win10系统安装Nginx的详细步骤
- 3017次 6 使用Nginx部署Vue项目全过程及踩坑记录
- 2970次 7 实现远程开机或者唤醒睡眠的电脑的方法
- 2857次 8 系统之家分享windows server 2019 无法安装AMD Radeon RX 6600 XT显卡驱动的解决方法
- 2563次 9 登录远程桌面时遇到“由于客户端检测到一个协议错误(代码0x1104)”
- 2500次 10 Nginx配置-日志格式配置方式
人气教程排行
- 133871次 1 kimi智能助手网页版入口 kimi智能助手官网地址
- 94779次 2 win7旗舰版激活密钥大全
- 61092次 3 win10企业版激活密钥免费大全 win10企业版激活密钥2024最新
- 57446次 4 联想笔记本进入bios的三种方法 联想笔记本怎么进入bios
- 52529次 5 打印机为什么打印出来是黑的_打印出来纸张表面黑的解决方法
- 39959次 6 笔记本电脑序列号在哪|笔记本电脑序列号怎么看
- 34047次 7 对于目标文件系统文件过大无法复制到u盘怎么解决方法
- 33567次 8 kimi ai网页版地址分享 kimi ai官网地址入口
- 32927次 9 键盘全部按键没反应的解决方法 键盘被锁住按什么键恢复
- 31898次 10 键盘win键无效的解决办法 电脑win键失效怎么办?
站长推荐
- 14254次 1 Win11怎么激活?Win11系统永久激活方法汇总(附激活码)
- 12470次 2 如何用u盘装系统?用系统城U盘启动制作盘安装Win10系统教程
- 7188次 3 联想拯救者win10一键恢复如何使用_联想win10一键还原孔使用方法
- 6469次 4 怎么在u盘pe下给电脑系统安装ahci驱动
- 6004次 5 华硕笔记本bios utility ez mode设置图解以及切换成传统bios界面方法华硕笔记本bios utility ez mode设置图解以及切换成传统bios界面方法
- 5600次 6 联想电脑开机出现PXE-MOF:Exiting Intel PXE ROM怎么解决
- 3808次 7 win10怎么改为uefi启动_win10系统设置uefi启动模式的方法
- 2905次 8 MAC系统 win7/10/11电脑如何恢复到出厂系统 怎么把电脑恢复出厂设置
- 2532次 9 CentOS 8 系统图形化安装教程(超详细)
- 2442次 10 win10系统下检测不到独立显卡如何解决
热门系统下载
- 8734次 1 雨林木风Win10专业版64位纯净版系统官方下载
- 7172次 2 Windows Server 2019 官方原版系统64位系统下载
- 6290次 3 Windows Server 2008 R2 简体中文官方原版64位系统下载
- 6262次 4 Windows Server 2008 简体中文官方原版32位系统下载
- 5525次 5 网吧游戏专用Win7 Sp1 64位免激活旗舰版 V2021.05
- 5408次 6 Win11官方最新版系统下载_Ghost Win11 22000.434(KB5009566)专业免激活版下载
- 5337次 7 Windows Server 2012 R2 官方原版系统64位系统下载
- 4968次 8 系统之家最新GHOST WIN7 X64 纯净万能旗舰版系统下载