史上最便捷搭建 ZooKeeper 服务器的方法
时间:2020-06-09来源:www.pcxitongcheng.com作者:电脑系统城
什么是 ZooKeeper
ZooKeeper 是 Apache 的一个顶级项目,为分布式应用提供高效、高可用的分布式协调服务,提供了诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知和分布式锁等分布式基础服务。由于 ZooKeeper 便捷的使用方式、卓越的性能和良好的稳定性,被广泛地应用于诸如 Hadoop、HBase、Kafka 和 Dubbo 等大型分布式系统中。

ZooKeeper 有三种运行模式:单机模式、伪集群模式和集群模式。
- 单机模式:这种模式一般适用于开发测试环境,一方面我们没有那么多机器资源,另外就是平时的开发调试并不需要极好的稳定性。
- 集群模式:一个 ZooKeeper 集群通常由一组机器组成,一般 3 台以上就可以组成一个可用的 ZooKeeper 集群了。组成 ZooKeeper 集群的每台机器都会在内存中维护当前的服务器状态,并且每台机器之间都会互相保持通信。
- 伪集群模式:这是一种特殊的集群模式,即集群的所有服务器都部署在一台机器上。当你手头上有一台比较好的机器,如果作为单机模式进行部署,就会浪费资源,这种情况下,ZooKeeper允许你在一台机器上通过启动不同的端口来启动多个 ZooKeeper 服务实例,以此来以集群的特性来对外服务。
ZooKeeper 的相关知识
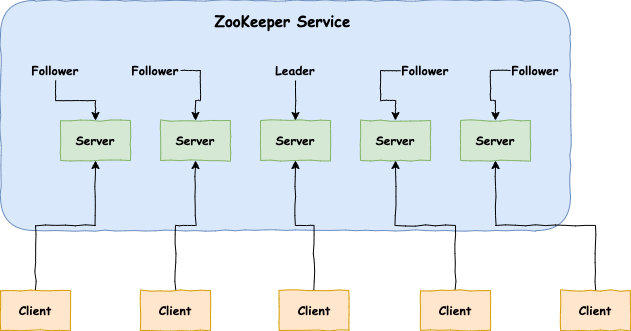
ZooKeeper 中的角色
- 领导者(leader):负责进行投票的发起和决议,更新系统状态
- 跟随者(follower):用于接收客户端请求并给客户端返回结果,在选主过程中进行投票
- 观察者(observer):可以接受客户端连接,将写请求转发给 leader,但是observer不参加投票的过程,只是为了扩展系统,提高读取的速度。
ZooKeeper 的数据模型
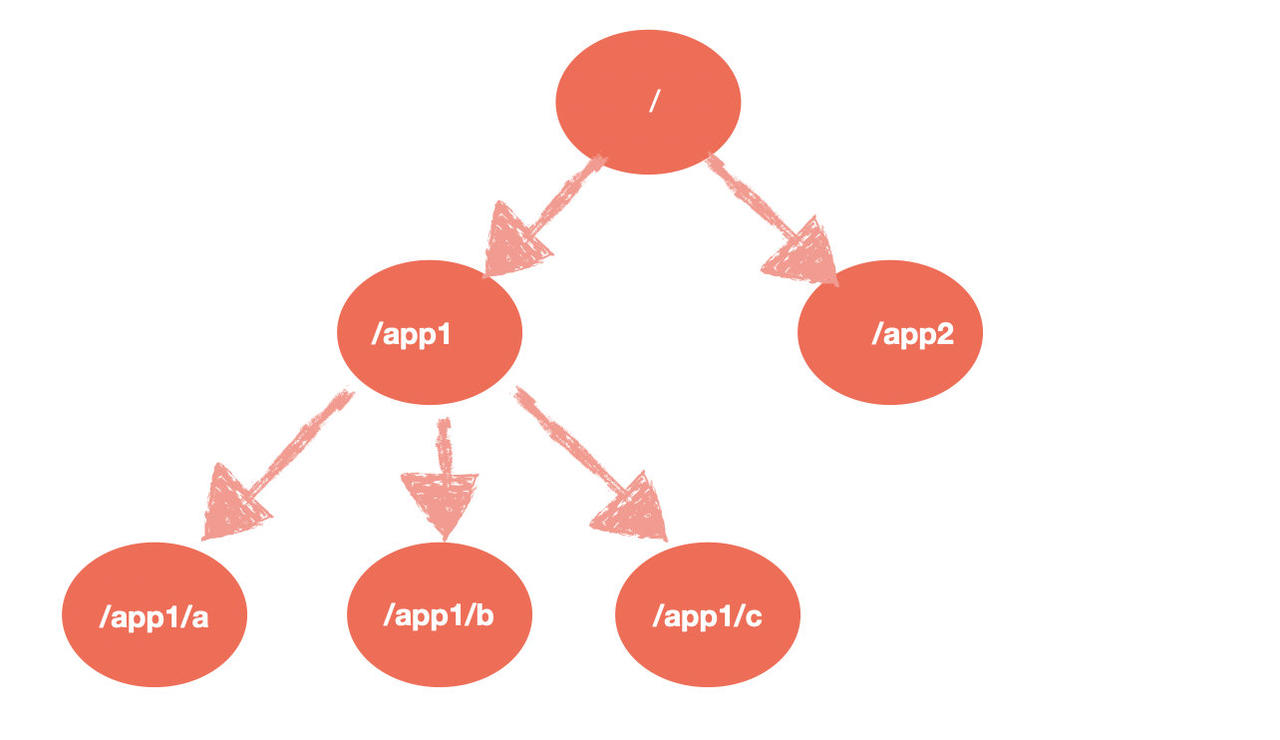
- 层次化的目录结构,命名符合常规文件系统规范,类似于 Linux
- 每个节点在 ZooKeeper 中叫做 Znode,并且其有一个唯一的路径标识
- 节点 Znode 可以包含数据和子节点,但是 EPHEMERAL 类型的节点不能有子节点
- Znode 中的数据可以有多个版本,比如某一个路径下存有多个数据版本,那么查询这个路径下的数据就需要带上版本
- 客户端应用可以在节点上设置监视器
- 节点不支持部分读写,而是一次性完整读写
ZooKeeper 的节点特性
ZooKeeper 节点是生命周期的,这取决于节点的类型。在 ZooKeeper 中,节点根据持续时间可以分为持久节点(PERSISTENT)、临时节点(EPHEMERAL),根据是否有序可以分为顺序节点(SEQUENTIAL)、和无序节点(默认是无序的)。
持久节点一旦被创建,除非主动移除,不然一直会保存在 ZooKeeper 中(不会因为创建该节点的客户端的会话失效而消失),临时节点。
ZooKeeper 的应用场景
ZooKeeper 是一个高可用的分布式数据管理与系统协调框架。基于对 Paxos 算法的实现,使该框架保证了分布式环境中数据的强一致性,也正是基于这样的特性,使得 ZooKeeper 解决很多分布式问题。
值得注意的是,ZooKeeper 并非天生就是为这些应用场景设计的,都是后来众多开发者根据其框架的特性,利用其提供的一系列 API 接口(或者称为原语集),摸索出来的典型使用方法。
数据发布与订阅(配置中心)
发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据发布到 ZooKeeper 节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。例如全局的配置信息,服务式服务框架的服务地址列表等就非常适合使用。
应用中用到的一些配置信息放到ZK上进行集中管理。这类场景通常是这样:应用在启动的时候会主动来获取一次配置,同时,在节点上注册一个 Watcher,这样一来,以后每次配置有更新的时候,都会实时通知到订阅的客户端,从来达到获取最新配置信息的目的。 分布式搜索服务中,索引的元信息和服务器集群机器的节点状态存放在 ZooKeeper 的一些指定节点,供各个客户端订阅使用。分布式日志收集系统。这个系统的核心工作是收集分布在不同机器的日志。收集器通常是按照应用来分配收集任务单元,因此需要在 ZooKeeper 上创建一个以应用名作为 path 的节点 P,并将这个应用的所有机器 IP,以子节点的形式注册到节点 P 上,这样一来就能够实现机器变动的时候,能够实时通知到收集器调整任务分配。 系统中有些信息需要动态获取,并且还会存在人工手动去修改这个信息的发问。通常是暴露出接口,例如 JMX 接口,来获取一些运行时的信息。引入 ZooKeeper 之后,就不用自己实现一套方案了,只要将这些信息存放到指定的 ZooKeeper 节点上即可。 注意:在上面提到的应用场景中,有个默认前提是:数据量很小,但是数据更新可能会比较快的场景。
负载均衡
这里说的负载均衡是指软负载均衡。在分布式环境中,为了保证高可用性,通常同一个应用或同一个服务的提供方都会部署多份,达到对等服务。而消费者就须要在这些对等的服务器中选择一个来执行相关的业务逻辑,其中比较典型的是消息中间件中的生产者,消费者负载均衡。
命名服务(Naming Service)
命名服务也是分布式系统中比较常见的一类场景。在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。被命名的实体通常可以是集群中的机器,提供的服务地址,远程对象等等——这些我们都可以统称他们为名字(Name)。其中较为常见的就是一些分布式服务框架中的服务地址列表。通过调用ZK提供的创建节点的API,能够很容易创建一个全局唯一的 path,这个 path就可以作为一个名称。
阿里巴巴集团开源的分布式服务框架 Dubbo 中使用 ZooKeeper 来作为其命名服务,维护全局的服务地址列表。在 Dubbo 实现中: 服务提供者在启动的时候,向 ZooKeeper 上的指定节点 /dubbo/${serviceName}/providers 目录下写入自己的 URL 地址,这个操作就完成了服务的发布。 服务消费者启动的时候,订阅 /dubbo/${serviceName}/providers 目录下的提供者 URL 地址, 并向 /dubbo/${serviceName} /consumers 目录下写入自己的 URL 地址。 注意,所有向 ZooKeeper 上注册的地址都是临时节点,这样就能够保证服务提供者和消费者能够自动感应资源的变化。
另外,Dubbo 还有针对服务粒度的监控,方法是订阅 /dubbo/${serviceName} 目录下所有提供者和消费者的信息。
分布式通知/协调
ZooKeeper 中特有 watcher 注册与异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对 ZooKeeper 上同一个 Znode 进行注册,监听 Znode 的变化(包括 Znode 本身内容及子节点的),其中一个系统 update 了 Znode,那么另一个系统能够收到通知,并作出相应处理。
另一种心跳检测机制:检测系统和被检测系统之间并不直接关联起来,而是通过zk上某个节点关联,大大减少系统耦合。 另一种系统调度模式:某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台作的一些操作,实际上是修改了 ZooKeeper 上某些节点的状态,而 ZooKeeper 就把这些变化通知给他们注册 Watcher 的客户端,即推送系统,于是,作出相应的推送任务。
另一种工作汇报模式:一些类似于任务分发系统,子任务启动后,到 ZooKeeper 来注册一个临时节点,并且定时将自己的进度进行汇报(将进度写回这个临时节点),这样任务管理者就能够实时知道任务进度。
分布式锁
分布式锁,这个主要得益于 ZooKeeper 为我们保证了数据的强一致性。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
所谓保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把 ZooKeeper 上的一个 Znode 看作是一把锁,通过 create znode 的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。控制时序,就是所有视图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序了。做法和上面基本类似,只是这里 /distribute_lock 已经预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的属性控制:CreateMode.EPHEMERAL_SEQUENTIAL 来指定)。ZooKeeper 的父节点(/distribute_lock)维持一份 sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。
- 由于同一节点下子节点名称不能相同,所以只要在某个节点下创建 Znode,创建成功即表明加锁成功。注册监听器监听此 Znode,只要删除此 Znode 就通知其他客户端来加锁。
- 创建临时顺序节点:在某个节点下创建节点,来一个请求则创建一个节点,由于是顺序的,所以序号最小的获得锁,当释放锁时,通知下一序号获得锁。
分布式队列
队列方面,简单来说有两种,一种是常规的先进先出队列,另一种是等队列的队员聚齐以后才按照顺序执行。对于第一种的队列和上面讲的分布式锁服务中控制时序的场景基本原理一致,这里就不赘述了。
第二种队列其实是在 FIFO 队列的基础上作了一个增强。通常可以在 /queue 这个 Znode 下预先建立一个 /queue/num 节点,并且赋值为 n(或者直接给 /queue 赋值 n),表示队列大小,之后每次有队列成员加入后,就判断下是否已经到达队列大小,决定是否可以开始执行了。这种用法的典型场景是,分布式环境中,一个大任务 Task A,需要在很多子任务完成(或条件就绪)情况下才能进行。这个时候,凡是其中一个子任务完成(就绪),那么就去 /taskList 下建立自己的临时时序节点(CreateMode.EPHEMERAL_SEQUENTIAL),当 /taskList 发现自己下面的子节点满足指定个数,就可以进行下一步按序进行处理了。
使用 dokcer-compose 搭建集群
上面我们介绍了关于 ZooKeeper 有这么多的应用场景,那么接下来我们就先学习如何搭建 ZooKeeper 集群然后再进行实战上面的应用场景。
文件的目录结构如下:
- ├── docker-compose.yml
编写 docker-compose.yml 文件
docker-compose.yml 文件内容如下:
- version: '3.4'
- services:
- zoo1:
- image: zookeeper
- restart: always
- hostname: zoo1
- ports:
- - 2181:2181
- environment:
- ZOO_MY_ID: 1
- ZOO_SERVERS: server.1=0.0.0.0:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
- zoo2:
- image: zookeeper
- restart: always
- hostname: zoo2
- ports:
- - 2182:2181
- environment:
- ZOO_MY_ID: 2
- ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=0.0.0.0:2888:3888;2181 server.3=zoo3:2888:3888;2181
- zoo3:
- image: zookeeper
- restart: always
- hostname: zoo3
- ports:
- - 2183:2181
- environment:
- ZOO_MY_ID: 3
- ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=0.0
在这个配置文件中,Docker 运行了 3 个 ZooKeeper 镜像,通过 ports 字段分别将本地的 2181,2182,2183 端口绑定到对应容器的 2181 端口上。
- ZOO_MY_ID 和 ZOO_SERVERS 是搭建 ZooKeeper 集群需要的两个环境变量。ZOO_MY_ID 标识服务的 id,为 1-255 之间的整数,必须在集群中唯一。ZOO_SERVERS 是集群中的主机列表。
在 docker-compose.yml 所在目录下执行 docker-compose up,可以看到启动的日志。
连接 ZooKeeper
将集群启动起来以后我们可以连接 ZooKeeper 对其进行节点的相关操作。
- 首先我们需要将 ZooKeeper 下载下来。ZooKeeper 下载地址。
- 将其解压
- 进入其 conf 目录中,将 zoo_sample .cfg 改成 zoo.cfg
配置文件说明:
- # The number of milliseconds of each tick
- # tickTime:CS 通信心跳数
- # ZooKeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime 以毫秒为单位。
- tickTime=2000
- # The number of ticks that the initial
- # synchronization phase can take
- # initLimit:LF初始通信时限
- # 集群中的 follower 服务器(F)与 leader 服务器(L)之间初始连接时能容忍的最多心跳数(tickTime 的数量)。
- initLimit=5
- # The number of ticks that can pass between
- # sending a request and getting an acknowledgement
- # syncLimit:LF同步通信时限
- # 集群中的 follower 服务器与 leader 服务器之间请求和应答之间能容忍的最多心跳数(tickTime 的数量)。
- syncLimit=2
- # the directory where the snapshot is stored.
- # do not use /tmp for storage, /tmp here is just
- # example sakes.
- # dataDir:数据文件目录
- # ZooKeeper 保存数据的目录,默认情况下,ZooKeeper 将写数据的日志文件也保存在这个目录里。
- dataDir=/data/soft/zookeeper-3.4.12/data
- # dataLogDir:日志文件目录
- # ZooKeeper 保存日志文件的目录。
- dataLogDir=/data/soft/zookeeper-3.4.12/logs
- # the port at which the clients will connect
- # clientPort:客户端连接端口
- # 客户端连接 ZooKeeper 服务器的端口,ZooKeeper 会监听这个端口,接受客户端的访问请求。
- clientPort=2181
- # the maximum number of client connections.
- # increase this if you need to handle more clients
- #maxClientCnxns=60
- #
- # Be sure to read the maintenance section of the
- # administrator guide before turning on autopurge.
- #
- # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
- #
- # The number of snapshots to retain in dataDir
- #autopurge.snapRetainCount=3
- # Purge task interval in hours
- # Set to "0" to disable auto purge feature
- #autopurge.purgeInterval=1
- # 服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口)
- # 这个配置项的书写格式比较特殊,规则如下:
- # server.N=YYY:A:B
- # 其中 N 表示服务器编号,YYY 表示服务器的 IP 地址,A 为 LF 通信端口,表示该服务器与集群中的 leader
可以不修改zoo.cfg,默认配置就行,接下来在解压后的 bin 目录中执行命令 ./zkCli.sh -server 127.0.0.1:2181 就能进行连接了。
- Welcome to ZooKeeper!
- 2020-06-01 15:03:52,512 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1025] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
- JLine support is enabled
- 2020-06-01 15:03:52,576 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@879] - Socket connection established to localhost/127.0.0.1:2181, initiating session
- 2020-06-01 15:03:52,599 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1299] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x100001140080000, negotiated timeout = 30000
- WATCHER::
- WatchedEvent state:SyncConnected type:None path:null
- [zk: 127.0.0.1:2181(CONNECTED) 0]
接下来我们可以使用命令查看节点了。
使用 ls 命令查看当前 ZooKeeper 中所包含的内容。
命令:ls /
- [zk: 127.0.0.1:2181(CONNECTED) 10] ls /
- [zookeeper]
创建了一个新的 Znode 节点“ zk ”以及与它关联的字符串。
命令:create /zk myData
- [zk: 127.0.0.1:2181(CONNECTED) 11] create /zk myData
- Created /zk
- [zk: 127.0.0.1:2181(CONNECTED) 12] ls /
- [zk, zookeeper]
- [zk: 127.0.0.1:2181(CONNECTED) 13]
获取 Znode 节点 zk。
命令:get /zk
- [zk: 127.0.0.1:2181(CONNECTED) 13] get /zk
- myData
- cZxid = 0x400000008
- ctime = Mon Jun 01 15:07:50 CST 2020
- mZxid = 0x400000008
- mtime = Mon Jun 01 15:07:50 CST 2020
- pZxid = 0x400000008
- cversion = 0
- dataVersion = 0
- aclVersion = 0
- ephemeralOwner = 0x0
- dataLength = 6
- numChildren = 0
删除 Znode 节点 zk。
命令:delete /zk
- [zk: 127.0.0.1:2181(CONNECTED) 14] delete /zk
- [zk: 127.0.0.1:2181(CONNECTED) 15] ls /
- [zookeeper]
由于篇幅有限,下篇文章会根据上面提到的 ZooKeeper 应用场景逐一进行用代码进行实现。
相关信息
-



-
-
2024-07-07
myeclipse怎么导入tomcat教程 -
2024-07-07
myeclipse如何启动tomcat -
2024-07-07
myeclipse如何绑定tomcat
-
-

-
 Nginx配置-日志格式配置方式
Nginx配置-日志格式配置方式上线了一个小的预约程序,配置通过Nginx进行访问入口,默认的日志是没有请求时间的,因此需要配置一下,将每一次的请求的访问响应时间记录出来,备查与优化使用....
2023-03-17
热门系统总排行
- 8734次 1 雨林木风Win10专业版64位纯净版系统官方下载
- 5408次 2 Win11官方最新版系统下载_Ghost Win11 22000.434(KB5009566)专业免激活版下载
- 4857次 3 电脑公司ghost win7 64位纯净专业版v2019.08
- 3296次 4 最新游戏专用Win11系统下载_游戏专用Ghost Win11 64位极速免激活专业版下载
- 2939次 5 深度技术 GHOST WIN10 X64 纯净版 V2019.09(64位)
- 2721次 6 Win10 21H1 esd镜像系统下载_Win10 21H1 64位免激活官方正式版下载V2021.04
- 2472次 7 深度技术 Ghost Win10 64位 免激活专业稳定版官网下载 V2021.12
- 2330次 8 电脑系统城ghost win7 sp132位 经典标准版 V2019.11












系统教程栏目
栏目热门教程
- 27246次 1 浏览器控制台报错Failed to load module script:解决方法
- 6145次 2 windows server2012上配置IIS全过程(附详细步骤)
- 5690次 3 解决Navicat 连接服务器不成功的问题
- 3671次 4 Nginx访问本地静态资源详细步骤(推荐)
- 3131次 5 win10系统安装Nginx的详细步骤
- 3017次 6 使用Nginx部署Vue项目全过程及踩坑记录
- 2970次 7 实现远程开机或者唤醒睡眠的电脑的方法
- 2857次 8 系统之家分享windows server 2019 无法安装AMD Radeon RX 6600 XT显卡驱动的解决方法
- 2563次 9 登录远程桌面时遇到“由于客户端检测到一个协议错误(代码0x1104)”
- 2500次 10 Nginx配置-日志格式配置方式
人气教程排行
- 133871次 1 kimi智能助手网页版入口 kimi智能助手官网地址
- 94779次 2 win7旗舰版激活密钥大全
- 61092次 3 win10企业版激活密钥免费大全 win10企业版激活密钥2024最新
- 57446次 4 联想笔记本进入bios的三种方法 联想笔记本怎么进入bios
- 52529次 5 打印机为什么打印出来是黑的_打印出来纸张表面黑的解决方法
- 39959次 6 笔记本电脑序列号在哪|笔记本电脑序列号怎么看
- 34047次 7 对于目标文件系统文件过大无法复制到u盘怎么解决方法
- 33567次 8 kimi ai网页版地址分享 kimi ai官网地址入口
- 32927次 9 键盘全部按键没反应的解决方法 键盘被锁住按什么键恢复
- 31898次 10 键盘win键无效的解决办法 电脑win键失效怎么办?
站长推荐
- 14254次 1 Win11怎么激活?Win11系统永久激活方法汇总(附激活码)
- 12470次 2 如何用u盘装系统?用系统城U盘启动制作盘安装Win10系统教程
- 7188次 3 联想拯救者win10一键恢复如何使用_联想win10一键还原孔使用方法
- 6469次 4 怎么在u盘pe下给电脑系统安装ahci驱动
- 6004次 5 华硕笔记本bios utility ez mode设置图解以及切换成传统bios界面方法华硕笔记本bios utility ez mode设置图解以及切换成传统bios界面方法
- 5600次 6 联想电脑开机出现PXE-MOF:Exiting Intel PXE ROM怎么解决
- 3808次 7 win10怎么改为uefi启动_win10系统设置uefi启动模式的方法
- 2905次 8 MAC系统 win7/10/11电脑如何恢复到出厂系统 怎么把电脑恢复出厂设置
- 2532次 9 CentOS 8 系统图形化安装教程(超详细)
- 2442次 10 win10系统下检测不到独立显卡如何解决
热门系统下载
- 8734次 1 雨林木风Win10专业版64位纯净版系统官方下载
- 7172次 2 Windows Server 2019 官方原版系统64位系统下载
- 6290次 3 Windows Server 2008 R2 简体中文官方原版64位系统下载
- 6262次 4 Windows Server 2008 简体中文官方原版32位系统下载
- 5525次 5 网吧游戏专用Win7 Sp1 64位免激活旗舰版 V2021.05
- 5408次 6 Win11官方最新版系统下载_Ghost Win11 22000.434(KB5009566)专业免激活版下载
- 5337次 7 Windows Server 2012 R2 官方原版系统64位系统下载
- 4968次 8 系统之家最新GHOST WIN7 X64 纯净万能旗舰版系统下载