Kona JDK 在腾讯大数据领域内的实践与发展
时间:2020-03-16来源:电脑系统城作者:电脑系统城
一、Tencent Kona 缘起
1. OpenJDK
经常听人谈到 OpenJDK,那它到底是什么呢?相信大家都听说过 Java SE、ME、EE等规范, 通常意义上对 Open JDK 的定义指:Java SE规范的一个免费和开源参考实现。
最早在2006年时,Sun承诺逐步开源核心 Java Platform,包括hotspot、Complier和类库等;第二年,Redhat加入,并发布IcedTea,也就是完全基于GNU自由软件构建的版本。
2010年时发生了一个非常大的变化,Oracle从Sun手中接过Stewardship,IBM加入并放弃Apache Harmony,Apple也加入OpenJDK。
2014年,JDK 8发布,它是迄今为止采纳速度最快和接受程度最高的版本,至今仍是生产环境的主力。业界今年的调查统计显示, JDK8 仍然是几乎所有厂商最主要的生产版本JDK。
2017年,经过三年的研发,JAVA 9发布了,这一年发生了一系列令人目不暇接的变化。
首先,从技术层面, JDK引入了原生的模块化系统,也就是 Jigsaw 项目 – JPMS(Java Platform Module System),JPMS为未来Java语言和JDK快速发展驱除了一些障碍,但是也带来了一些兼容性的问题,JDK 9并未像预期一般成为JDK 8的广泛替代者。
其次,Java从特性驱动转变为时间驱动的发布模式。这是由于云计算等领域的快速发展,给Java带来了非常大的挑战。
传统的发布模式,理想情况下大概以两年为一个发布周期,但是我们在实际的JDK 9开发中,又拖了一年左右,即使是这样仍然有一些计划的工作没有做完。
长开发周期导致大量已经就绪的技术,迟迟不能进入生产阶段,大大降低了Java发展和迭代的速度。为了适应这个变化,JDK切换为以半年为周期的新发布模式。
第三,Oracle JDK开源商业特性,并且变更Oracle JDK收费策略,大大缩短了JDK免费支持周期。
令人欣慰的是,虽然Java经历了“收费”风波,事实上,今天 OpenJDK 社区的活跃度和参与度都大大提高了。腾讯、微软等厂商都加入了社区,并且开始积极贡献OpenJDK。

2. Oracle JDK
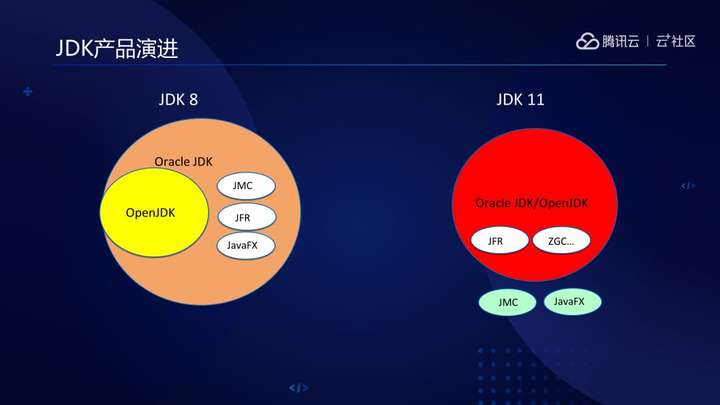
Oracle JDK和OpenJDK之间是什么关系呢?简单做个对比,Oracle JDK 8可以认为是OpenJDK的一个超集,包含了其自身的商业特性。
但发展到JDK11之后,整个JDK的产品形态发生了一个很大的变化,从一个大的单体应用,作了一定的解耦,JMC、OpenJFX等以软件包的形式独立于JDK之外,Oracle也将其商业特性都开源了出来,所以Oracle JDK 11和OpenJDK 11仅存在License的不同。
3. Tencent Kona JDK
Tencent Kona JDK是基于OpenJDK主分支开发的JDK发行版,并坚持下面几个基本原则。
第一,它是免费的,大家可以放心使用。
第二,我们会针对JDK8、JDK11这样的LTS版本,提供长期、可靠的支持。
第三, Kona JDK经过腾讯海量的负载验证,确保生产环境就绪的能力。

那么,Tencent Kona 和Open JDK之间是什么关系?有哪些优势和发展思路呢?
首先,我们承诺Kona是一个“friend-Fork”,并会最大化地保证Kona兼容性。Kona团队与大量内部JDK使用者和合作伙伴团队等进行了广泛沟通,提供高标准的兼容性和稳定性、可靠性、性能。
Kona JDK不会为了创新而创新,因为伤害JDK兼容性其实是对企业技术投资的不负责任,也会给使用者带来未来的生产迁移和维护成本。
另外,基于腾讯海量的大数据、云等各种Java/JVM负载,我们会将如此规模场景下的实践心得和技术沉淀分享出来,并逐步以Bugfix、Enhancement或者是Feature的形式开源给大家使用。
从社区参与的角度,我们已经与Open JDK社区和Oracle Java产品团队作了沟通,并且整个社区沟通邮件中明确了上面的原则,严格按照社区的治理标准来要求自己,不做食利者。

二、OpenJDK技术趋势
回到OpenJDK本身,现在有哪些值得关注的主要趋势呢?
在这里引用John Rose(Oracle JVM Architect)的总结。

1. Java-on-Java
Java-on-Java,指的是以Java语言开发JVM虚拟机。
例如,目前C1/C2 JIT(Just-In-Time)编译器,主要是用C++开发的,代码已经非常难以改进,Oracle在GraalVM等项目中,逐步实践了基于Java的JVM虚拟机,其技术将逐步成为未来JVM的核心。
目前总体还处于实验性阶段,但是已经表现出非常可观的成果。例如,利用其native-machine和SubstrateVM,在启动速度和内存Footprint等方面能够有非常突破性的提高,甚至简单程序可以看到30倍的改进。
虽然这是基于Close-World-Assumption,对Java的动态特性有所取舍,广泛实践仍存在距离,但未来可期。
2. 偿还Java语言或者JVM设计实现的一些欠账
Java设计中,除了原始数据类型,其他都是对象。对象头、多态支持等开销明显,而这些对于数据(Data),往往是一种overhead,而不是数据本身的需求。
于此同时,复杂的引用关系带来着内存布局上的复杂性,难以充分利用现代CPU的缓存结构。Java语言也难以高效、优雅地表达部分复杂数据结构和范型等,这些问题将在Valhalla等项目中得到解决。
3. Java语法的改变
Java的语法在Amber/Valhalla等项目中逐步演进,提高了代码开发的效率和代码质量。比如JAVA 10中提供的本地变量类型推断,通过上下文推断简化代码编写,提高代码可读性。后续正在预览阶段的Switch Expression等,通过expression代替statements,大大提高语言表达能力,提高开发效率和良好实践。
4. 操作硬件层次能力提升
OpenJDK 可以更快、更直接地去操作硬件层次,主要是用于Panama等项目开发中。例如为大数据、机器学习提供算力的支持,提供更好的本地代码交互能力、向量计算能力等等。
当然,还有提高并发编程和运行效率的Project Loom,引入Fiber/Continuation,解决目前Java并发开发/运行效率问题。还有广受期待的Pauseless GC等等,总的来说JVM正变得更加智能、高效。
三、大数据领域实践与发展
大家知道,主流大数据技术栈,要么是基于Java,要么是运行在JVM之上。Java和JVM提供的易用的语法、跨平台能力、广泛的工具、类库等等,让JVM成为大数据领域的无冕之王,目前来看几乎没有同等竞争对手。

但是,当我们真正开发维护超大规模集群、处理海量数据的时候,JVM就逐渐有些局限性了。
例如,在主流的Hadoop技术栈,NM等节点的堆大小直接影响到集群和数据规模,GC稳定性又与SLA密切相关,目前JVM在大堆GC方面,还远不算完美,需要进一步改进。
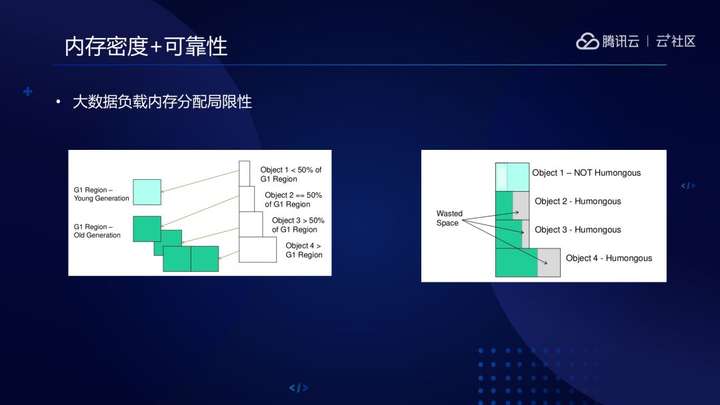
从大数据负载特点来看,经典GC算法存在一定程度的水土不服。我们知道目前的年代等设计,本就是基于一个实践经验“大部分对象较小并且生命短暂“,但是,在Spark SQL等大数据负载,经常可以见到大量的长生命周期大对象甚至超大对象分配。

大对象分配和初始化成本高昂,而且在G1 GC等基于Region的设计中,达到或者超过Region 50%大小的对象会占据一个或多个分区,剩余空间则被浪费掉,这一点限制着宝贵的内存资源利用效率。
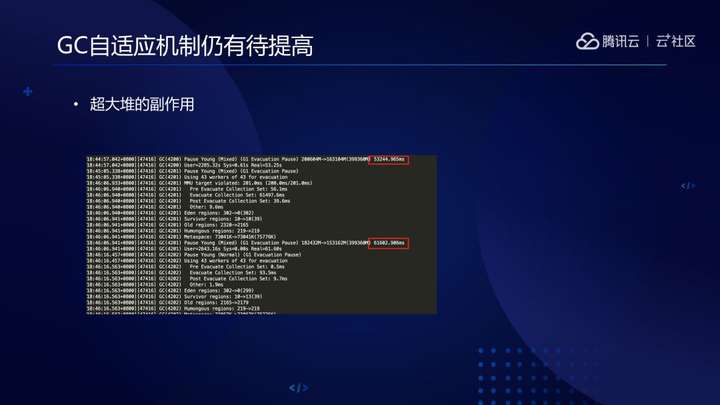
从大数据的业务特点来看,JVM机制也需要针对性修正和提高。例如,相当于一步大数据业务都是定时的离线计算,在一天中的不同时间段,应用行为变化较大,而目前JVM的自适应特性发生水土不服并不鲜见, G1 GC预测引擎连续预测失败导致的GC长暂停,有时会伤害SLA,针对性改进必不可少。
因为上面的种种局限,很多大数据框架,不得不费力去操作堆外,带来了研发和运维的效率问题。
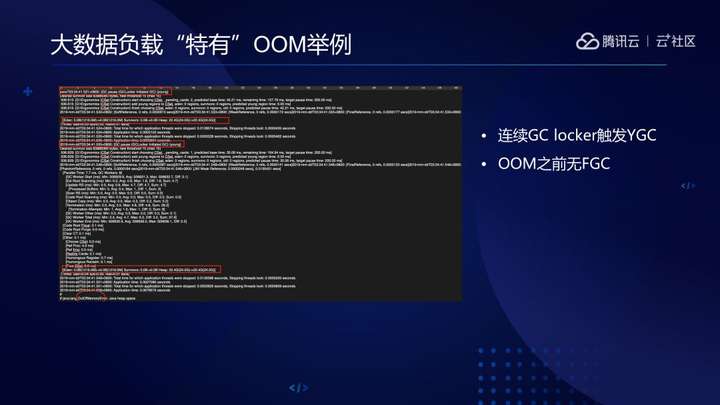
我们在生产实践中注意到,大数据应用中JNI进入临界区,GC Locker触发频繁的无意义Young GC与大对象分配合力,会导致JVM意外OOM,这个问题在大数据场景比较频繁,具体可以参考下图。
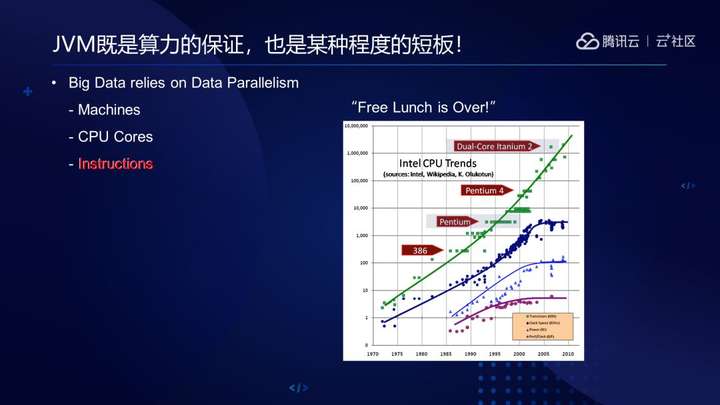
另外,不管是大数据还是机器学习,终归脱离不了一个核心,也就是算力。
大数据依赖于机器(集群)、线程(多核)和指令(SIMD)三种层次的数据并行计算。大概是2002年以后, CPU Core的频率已经基本上没有明显上升,甚至有所下降,生产负载扩展性越来越依赖于堆CPU、堆机器。分布式集群和多线程必不可少,但JVM层面在指令级别的优化尚未得到充分重视,充分利用指令并行能力是算力的保障之一。
JVM向量化/SIMD通常有三种手段:
第一,JNI直接使用native代码,但因为CPU的多变等原因而非常难以开发和维护。
第二,自己开发JVM Intrinsic,这对普通开发者来说并不不现实
第三,利用JVM提供的Auto-Vectorization能力,是比较可行的。


但是Auto-Vectorization能力局限性也很多,目前仅在C2提供 SupperWord Optimization,依赖于Counted Loop的Loop Unrolling,开发有难度且比较脆弱。

目前,OpenJDK孵化中的Vector API能够大大提高开发效率,进而提高性能,未来我们将积极推动其发展和成熟。

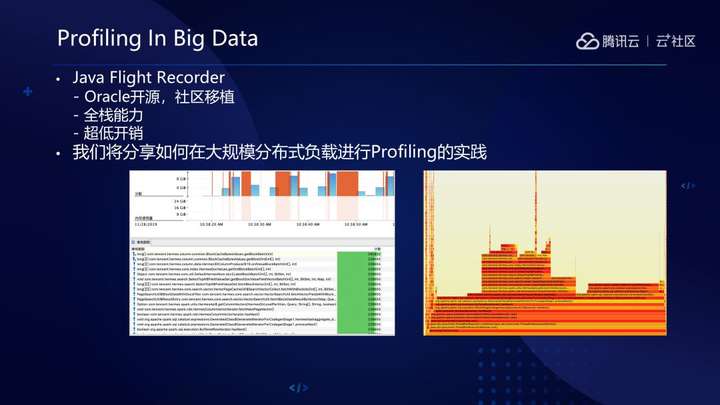
在大数据场景诊断和调优方面,Kona内部集成的Java Flight Recorder(Oracle开源)提供了生产环境可用的全栈JVM Profiling能力,并且提供了可以不用Heap Dump诊断memory leak的可能,这对于海量分布式集群、频繁大堆/超大堆的大数据场景,非常有帮助。

也有助于我们进一步整体理解大数据负载的通用开销,比如序列化/反序列化、内存(对象)分配等等。
我们会与社区一起增强jmap等SVC工具,优化通用开销,并向社区回馈和分享我们的经验。
四、Q&A
Q:杨老师,我想问一下腾讯云现在做Open JDK和Kona JDK有什么区别?做这个有什么优势呢?
A:Kona JDK是基于Open JDK主分支,基于海量的微服务、Serverless、大数据等实际应用场景的需求与痛点进行改进,目标定位于提供在相应场景的最佳Java运行环境和解决方案。
Kona JDK会尽量upstream特性,让Java生态的收益最大化,并且在特性选取上,充分考虑兼容性、成熟度和生产价值,强调为用户带来实实在在的效率和生产力。如果确实有个别特性或bug fix,不符合upstream到主分支的通用性标准、工作思路等,但只要存在较大的生产意义,Kona可能仍会选择提供。
我认为,从Java生态健康的角度,Kona JDK的意义和目的都不在于区别,而在于长期、可靠的支持,加速OpenJDK新特性生产化速度,增强数据科学、云计算等领域的Java基础实力。
讲师介绍
杨晓峰,腾讯高级技术专家,中国计算机协会(CCF)系统软件专委委员,目前负责TEG JDK团队、OpenJDK Committer。曾领导 Oracle Java Platform 北京核心类库团队、京东数据基础平台智能化系统研发团队等,出品专栏《Java核心技术36讲》,聚焦于Java/JVM等基础软件在大数据、云计算等前沿领域的演进和实践。
相关信息
-



-
-
2024-04-11
台式机电脑如何连接外接显示器 -
2024-04-11
小新系列打印机手机配置网络的方法教程 -
2024-04-11
Thinkpad 笔记本F1-F12快捷键分别是什么功能
-
-
 ThinkPad蓝牙鼠标如何配对
ThinkPad蓝牙鼠标如何配对ThinkPad蓝牙鼠标如何配对解答步骤41U5008鼠标驱动官网地址: https://support.lenovo.com/en_US/downloads/detail.page?&LegacyDocID=MIGR-67201 第一种方式是比较传统的:使...
2024-04-11
-
 USB接口无法识别设备的解决方法
USB接口无法识别设备的解决方法故障现象: USB设备U盘、移动硬盘等插入后提示无法识别的设备,确认设备本身正常,设备可加电,或插入设备后加电但无任何反应,无法使用。新型号机器多表现为黄色USB接口存在此问题,...
2024-04-11
热门系统总排行
- 8734次 1 雨林木风Win10专业版64位纯净版系统官方下载
- 5408次 2 Win11官方最新版系统下载_Ghost Win11 22000.434(KB5009566)专业免激活版下载
- 4857次 3 电脑公司ghost win7 64位纯净专业版v2019.08
- 3296次 4 最新游戏专用Win11系统下载_游戏专用Ghost Win11 64位极速免激活专业版下载
- 2939次 5 深度技术 GHOST WIN10 X64 纯净版 V2019.09(64位)
- 2721次 6 Win10 21H1 esd镜像系统下载_Win10 21H1 64位免激活官方正式版下载V2021.04
- 2472次 7 深度技术 Ghost Win10 64位 免激活专业稳定版官网下载 V2021.12
- 2330次 8 电脑系统城ghost win7 sp132位 经典标准版 V2019.11












系统教程栏目
栏目热门教程
- 20285次 1 打印机显示休眠不打印怎么办 打印机深度休眠不打印解决方法
- 15684次 2 安装惠普打印机出现“新设备现已连接”一直不动怎么办?
- 15660次 3 qq群文件下载位置详情
- 15084次 4 打印机打印显示发送传真怎么办 为什么点打印出来发送传真
- 14257次 5 怎么用手机号查快递详细教程
- 13569次 6 富士施乐DocuCentre S2110打印一体机怎么清零教程?
- 13171次 7 蓝牙耳机长按无反应怎么办 蓝牙耳机长按灯不亮的处理方法
- 13008次 8 富士施乐 DocuCentre S2011 双面打印设置方法
- 11100次 9 拯救者Y7000如何使用录屏功能
- 10555次 10 由于找不到vcruntime140.dll无法继续执行代码的解决方法
人气教程排行
- 133871次 1 kimi智能助手网页版入口 kimi智能助手官网地址
- 94779次 2 win7旗舰版激活密钥大全
- 61092次 3 win10企业版激活密钥免费大全 win10企业版激活密钥2024最新
- 57446次 4 联想笔记本进入bios的三种方法 联想笔记本怎么进入bios
- 52529次 5 打印机为什么打印出来是黑的_打印出来纸张表面黑的解决方法
- 39959次 6 笔记本电脑序列号在哪|笔记本电脑序列号怎么看
- 34047次 7 对于目标文件系统文件过大无法复制到u盘怎么解决方法
- 33567次 8 kimi ai网页版地址分享 kimi ai官网地址入口
- 32927次 9 键盘全部按键没反应的解决方法 键盘被锁住按什么键恢复
- 31898次 10 键盘win键无效的解决办法 电脑win键失效怎么办?
站长推荐
- 14254次 1 Win11怎么激活?Win11系统永久激活方法汇总(附激活码)
- 12470次 2 如何用u盘装系统?用系统城U盘启动制作盘安装Win10系统教程
- 7188次 3 联想拯救者win10一键恢复如何使用_联想win10一键还原孔使用方法
- 6469次 4 怎么在u盘pe下给电脑系统安装ahci驱动
- 6004次 5 华硕笔记本bios utility ez mode设置图解以及切换成传统bios界面方法华硕笔记本bios utility ez mode设置图解以及切换成传统bios界面方法
- 5600次 6 联想电脑开机出现PXE-MOF:Exiting Intel PXE ROM怎么解决
- 3808次 7 win10怎么改为uefi启动_win10系统设置uefi启动模式的方法
- 2905次 8 MAC系统 win7/10/11电脑如何恢复到出厂系统 怎么把电脑恢复出厂设置
- 2532次 9 CentOS 8 系统图形化安装教程(超详细)
- 2442次 10 win10系统下检测不到独立显卡如何解决
热门系统下载
- 8734次 1 雨林木风Win10专业版64位纯净版系统官方下载
- 7172次 2 Windows Server 2019 官方原版系统64位系统下载
- 6290次 3 Windows Server 2008 R2 简体中文官方原版64位系统下载
- 6262次 4 Windows Server 2008 简体中文官方原版32位系统下载
- 5525次 5 网吧游戏专用Win7 Sp1 64位免激活旗舰版 V2021.05
- 5408次 6 Win11官方最新版系统下载_Ghost Win11 22000.434(KB5009566)专业免激活版下载
- 5337次 7 Windows Server 2012 R2 官方原版系统64位系统下载
- 4968次 8 系统之家最新GHOST WIN7 X64 纯净万能旗舰版系统下载