为什么MySQL不推荐使用uuid或者雪花id作为主键?
时间:2020-08-31来源:www.pcxitongcheng.com作者:电脑系统城
在mysql中设计表的时候,mysql官方推荐不要使用uuid或者不连续不重复的雪花id(long形且唯一,单机递增),而是推荐连续自增的主键id,官方的推荐是auto_increment,那么为什么不建议采用uuid,使用uuid究竟有什么坏处?
本篇博客我们就来分析这个问题,探讨一下内部的原因。
本篇博客的目录
- mysql程序实例
- 使用uuid和自增id的索引结构对比
- 总结
一、mysql和程序实例
1.1.要说明这个问题,我们首先来建立三张表
分别是user_auto_key,user_uuid,user_random_key,分别表示自动增长的主键,uuid作为主键,随机key作为主键,其它我们完全保持不变.
根据控制变量法,我们只把每个表的主键使用不同的策略生成,而其他的字段完全一样,然后测试一下表的插入速度和查询速度:
注:这里的随机key其实是指用雪花算法算出来的前后不连续不重复无规律的id:一串18位长度的long值
id自动生成表:

用户uuid表
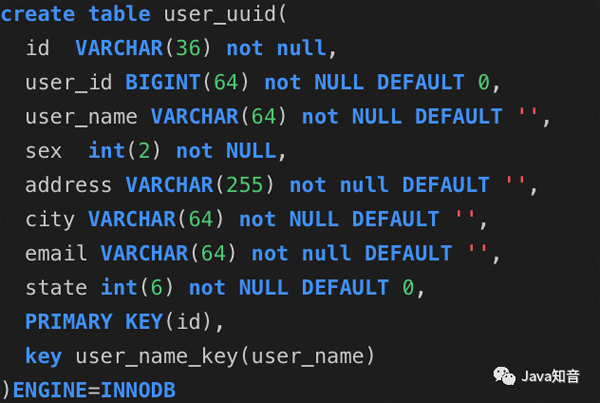
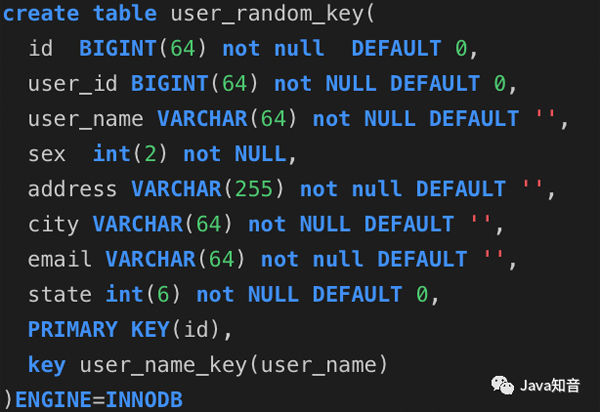
随机主键表:
1.2.光有理论不行,直接上程序,使用spring的jdbcTemplate来实现增查测试:
技术框架:springboot+jdbcTemplate+junit+hutool,程序的原理就是连接自己的测试数据库,然后在相同的环境下写入同等数量的数据,来分析一下insert插入的时间来进行综合其效率,为了做到最真实的效果,所有的数据采用随机生成,比如名字、邮箱、地址都是随机生成。
搜索Java知音公众号,回复“后端面试”,送你一份Java面试题宝典
- package com.wyq.mysqldemo;
- import cn.hutool.core.collection.CollectionUtil;
- import com.wyq.mysqldemo.databaseobject.UserKeyAuto;
- import com.wyq.mysqldemo.databaseobject.UserKeyRandom;
- import com.wyq.mysqldemo.databaseobject.UserKeyUUID;
- import com.wyq.mysqldemo.diffkeytest.AutoKeyTableService;
- import com.wyq.mysqldemo.diffkeytest.RandomKeyTableService;
- import com.wyq.mysqldemo.diffkeytest.UUIDKeyTableService;
- import com.wyq.mysqldemo.util.JdbcTemplateService;
- import org.junit.jupiter.api.Test;
- import org.springframework.beans.factory.annotation.Autowired;
- import org.springframework.boot.test.context.SpringBootTest;
- import org.springframework.util.StopWatch;
- import java.util.List;
- @SpringBootTest
- class MysqlDemoApplicationTests {
- @Autowired
- private JdbcTemplateService jdbcTemplateService;
- @Autowired
- private AutoKeyTableService autoKeyTableService;
- @Autowired
- private UUIDKeyTableService uuidKeyTableService;
- @Autowired
- private RandomKeyTableService randomKeyTableService;
- @Test
- void testDBTime() {
- StopWatch stopwatch = new StopWatch("执行sql时间消耗");
- /**
- * auto_increment key任务
- */
- final String insertSql = "INSERT INTO user_key_auto(user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?)";
- List<UserKeyAuto> insertData = autoKeyTableService.getInsertData();
- stopwatch.start("自动生成key表任务开始");
- long start1 = System.currentTimeMillis();
- if (CollectionUtil.isNotEmpty(insertData)) {
- boolean insertResult = jdbcTemplateService.insert(insertSql, insertData, false);
- System.out.println(insertResult);
- }
- long end1 = System.currentTimeMillis();
- System.out.println("auto key消耗的时间:" + (end1 - start1));
- stopwatch.stop();
- /**
- * uudID的key
- */
- final String insertSql2 = "INSERT INTO user_uuid(id,user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?,?)";
- List<UserKeyUUID> insertData2 = uuidKeyTableService.getInsertData();
- stopwatch.start("UUID的key表任务开始");
- long begin = System.currentTimeMillis();
- if (CollectionUtil.isNotEmpty(insertData)) {
- boolean insertResult = jdbcTemplateService.insert(insertSql2, insertData2, true);
- System.out.println(insertResult);
- }
- long over = System.currentTimeMillis();
- System.out.println("UUID key消耗的时间:" + (over - begin));
- stopwatch.stop();
- /**
- * 随机的long值key
- */
- final String insertSql3 = "INSERT INTO user_random_key(id,user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?,?)";
- List<UserKeyRandom> insertData3 = randomKeyTableService.getInsertData();
- stopwatch.start("随机的long值key表任务开始");
- Long start = System.currentTimeMillis();
- if (CollectionUtil.isNotEmpty(insertData)) {
- boolean insertResult = jdbcTemplateService.insert(insertSql3, insertData3, true);
- System.out.println(insertResult);
- }
- Long end = System.currentTimeMillis();
- System.out.println("随机key任务消耗时间:" + (end - start));
- stopwatch.stop();
- String result = stopwatch.prettyPrint();
- System.out.println(result);
- }
1.3.程序写入结果
user_key_auto写入结果:
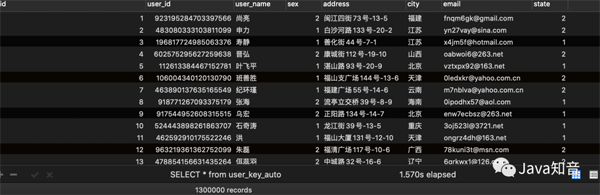
user_random_key写入结果:
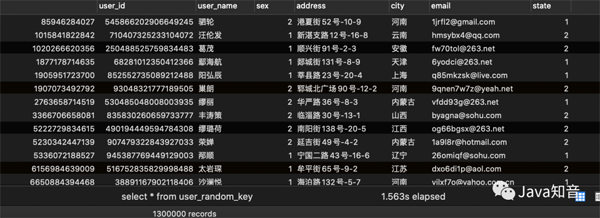
user_uuid表写入结果:
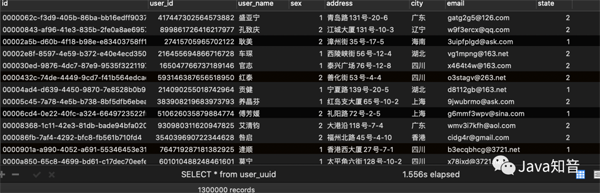
1.4.效率测试结果
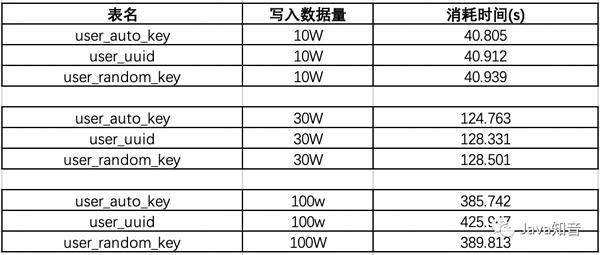
在已有数据量为130W的时候:我们再来测试一下插入10w数据,看看会有什么结果:

可以看出在数据量100W左右的时候,uuid的插入效率垫底,并且在后序增加了130W的数据,uudi的时间又直线下降。
时间占用量总体可以打出的效率排名为:auto_key>random_key>uuid,uuid的效率最低,在数据量较大的情况下,效率直线下滑。那么为什么会出现这样的现象呢?带着疑问,我们来探讨一下这个问题:
二、使用uuid和自增id的索引结构对比
2.1.使用自增id的内部结构
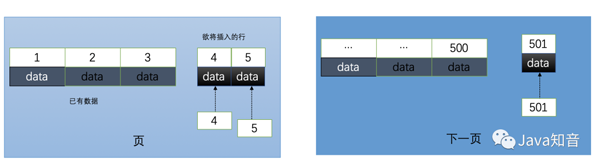
自增的主键的值是顺序的,所以Innodb把每一条记录都存储在一条记录的后面。当达到页面的最大填充因子时候(innodb默认的最大填充因子是页大小的15/16,会留出1/16的空间留作以后的 修改):
①下一条记录就会写入新的页中,一旦数据按照这种顺序的方式加载,主键页就会近乎于顺序的记录填满,提升了页面的最大填充率,不会有页的浪费
②新插入的行一定会在原有的最大数据行下一行,mysql定位和寻址很快,不会为计算新行的位置而做出额外的消耗
③减少了页分裂和碎片的产生
2.2.使用uuid的索引内部结构
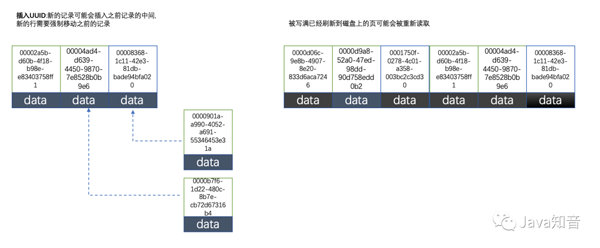
因为uuid相对顺序的自增id来说是毫无规律可言的,新行的值不一定要比之前的主键的值要大,所以innodb无法做到总是把新行插入到索引的最后,而是需要为新行寻找新的合适的位置从而来分配新的空间。
这个过程需要做很多额外的操作,数据的毫无顺序会导致数据分布散乱,将会导致以下的问题:
①写入的目标页很可能已经刷新到磁盘上并且从缓存上移除,或者还没有被加载到缓存中,innodb在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机IO
②因为写入是乱序的,innodb不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂导致移动大量的数据,一次插入最少需要修改三个页以上
③由于频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片
在把随机值(uuid和雪花id)载入到聚簇索引(innodb默认的索引类型)以后,有时候会需要做一次OPTIMEIZE TABLE来重建表并优化页的填充,这将又需要一定的时间消耗。
结论:使用innodb应该尽可能的按主键的自增顺序插入,并且尽可能使用单调的增加的聚簇键的值来插入新行
搜索Java知音公众号,回复“后端面试”,送你一份Java面试题宝典
2.3.使用自增id的缺点
那么使用自增的id就完全没有坏处了吗?并不是,自增id也会存在以下几点问题:
①别人一旦爬取你的数据库,就可以根据数据库的自增id获取到你的业务增长信息,很容易分析出你的经营情况
②对于高并发的负载,innodb在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争
③Auto_Increment锁机制会造成自增锁的抢夺,有一定的性能损失
附:Auto_increment的锁争抢问题,如果要改善需要调优innodb_autoinc_lock_mode的配置
三、总结
本篇博客首先从开篇的提出问题,建表到使用jdbcTemplate去测试不同id的生成策略在大数据量的数据插入表现,然后分析了id的机制不同在mysql的索引结构以及优缺点,深入的解释了为何uuid和随机不重复id在数据插入中的性能损耗,详细的解释了这个问题。
在实际的开发中还是根据mysql的官方推荐最好使用自增id,mysql博大精深,内部还有很多值得优化的点需要我们学习。
相关信息
-



-
-
2023-10-30
windows上的mysql服务突然消失提示10061 Unkonwn error问题及解决方案 -
2023-10-30
MySQL非常重要的日志bin log详解 -
2023-10-30
详解MySQL事务日志redo log
-
-
 MySQL的核心查询语句详解
MySQL的核心查询语句详解一、单表查询 1、排序 2、聚合函数 3、分组 4、limit 二、SQL约束 1、主键约束 2、非空约束 3、唯一约束 4、外键约束 5、默认值 三、多表查询 1、内连接 1)隐式内连接: 2)显式内连接: 2、外连接 1)左外连接 2)右外连接 四...
2023-10-30
-
 Mysql中如何删除表重复数据
Mysql中如何删除表重复数据Mysql删除表重复数据 表里存在唯一主键 没有主键时删除重复数据 Mysql删除表中重复数据并保留一条 准备一张表 用的是mysql8 大家自行更改 创建表并添加四条相同的数据...
2023-10-30
热门系统总排行
- 8726次 1 雨林木风Win10专业版64位纯净版系统官方下载
- 5395次 2 Win11官方最新版系统下载_Ghost Win11 22000.434(KB5009566)专业免激活版下载
- 4848次 3 电脑公司ghost win7 64位纯净专业版v2019.08
- 3285次 4 最新游戏专用Win11系统下载_游戏专用Ghost Win11 64位极速免激活专业版下载
- 2929次 5 深度技术 GHOST WIN10 X64 纯净版 V2019.09(64位)
- 2705次 6 Win10 21H1 esd镜像系统下载_Win10 21H1 64位免激活官方正式版下载V2021.04
- 2459次 7 深度技术 Ghost Win10 64位 免激活专业稳定版官网下载 V2021.12
- 2323次 8 电脑系统城ghost win7 sp132位 经典标准版 V2019.11












系统教程栏目
栏目热门教程
- 5100次 1 Mysql实现模糊查询的两种方式(like子句 、正则表达式)
- 4066次 2 一台电脑(windows系统)安装两个版本MYSQL方法步骤
- 3160次 3 DBeaver连接mysql数据库图文教程(超详细)
- 2850次 4 Mysql 5.7 新特性之 json 类型的增删改查操作和用法
- 2641次 5 MySQL安装服务时提示:Install/Remove of the Service Denied解决
- 2580次 6 MySQL无服务及服务无法启动的终极解决方案分享
- 2409次 7 Mysql中find_in_set()函数用法详解以及使用场景
- 2335次 8 银河麒麟V10安装MySQL8.0.28并实现远程访问
- 2134次 9 MySQL8.0 Command Line Client输入密码后出现闪退现象的原因以及解决方法总结
- 2086次 10 Mysql根据一个表的数据更新另一个表数据的SQL写法(三种写法)
人气教程排行
- 133852次 1 kimi智能助手网页版入口 kimi智能助手官网地址
- 94678次 2 win7旗舰版激活密钥大全
- 61046次 3 win10企业版激活密钥免费大全 win10企业版激活密钥2024最新
- 57442次 4 联想笔记本进入bios的三种方法 联想笔记本怎么进入bios
- 52523次 5 打印机为什么打印出来是黑的_打印出来纸张表面黑的解决方法
- 39952次 6 笔记本电脑序列号在哪|笔记本电脑序列号怎么看
- 34038次 7 对于目标文件系统文件过大无法复制到u盘怎么解决方法
- 33549次 8 kimi ai网页版地址分享 kimi ai官网地址入口
- 32916次 9 键盘全部按键没反应的解决方法 键盘被锁住按什么键恢复
- 31889次 10 键盘win键无效的解决办法 电脑win键失效怎么办?
站长推荐
- 14240次 1 Win11怎么激活?Win11系统永久激活方法汇总(附激活码)
- 12459次 2 如何用u盘装系统?用系统城U盘启动制作盘安装Win10系统教程
- 7178次 3 联想拯救者win10一键恢复如何使用_联想win10一键还原孔使用方法
- 6455次 4 怎么在u盘pe下给电脑系统安装ahci驱动
- 5994次 5 华硕笔记本bios utility ez mode设置图解以及切换成传统bios界面方法华硕笔记本bios utility ez mode设置图解以及切换成传统bios界面方法
- 5593次 6 联想电脑开机出现PXE-MOF:Exiting Intel PXE ROM怎么解决
- 3796次 7 win10怎么改为uefi启动_win10系统设置uefi启动模式的方法
- 2895次 8 MAC系统 win7/10/11电脑如何恢复到出厂系统 怎么把电脑恢复出厂设置
- 2526次 9 CentOS 8 系统图形化安装教程(超详细)
- 2435次 10 win10系统下检测不到独立显卡如何解决
热门系统下载
- 8726次 1 雨林木风Win10专业版64位纯净版系统官方下载
- 7163次 2 Windows Server 2019 官方原版系统64位系统下载
- 6282次 3 Windows Server 2008 R2 简体中文官方原版64位系统下载
- 6254次 4 Windows Server 2008 简体中文官方原版32位系统下载
- 5515次 5 网吧游戏专用Win7 Sp1 64位免激活旗舰版 V2021.05
- 5395次 6 Win11官方最新版系统下载_Ghost Win11 22000.434(KB5009566)专业免激活版下载
- 5325次 7 Windows Server 2012 R2 官方原版系统64位系统下载
- 4948次 8 系统之家最新GHOST WIN7 X64 纯净万能旗舰版系统下载